

Verstehen von Random Forest: Eine Ensemble-Methode
Das Random-Forest-Modell (RF), das erstmals 1995 von Tin Kam Ho vorgeschlagen wurde, ist eine Unterklasse von Ensemble-Lernmethoden, die für Klassifizierung und Regression eingesetzt werden. Eine Ensemble-Methode konstruiert eine Reihe von Klassifizierern - im Fall von RF eine Gruppe von Entscheidungsbäumen - und bestimmt das Label für jede Dateninstanz, indem es den gewichteten Durchschnitt der Ergebnisse jedes Klassifizierers bildet.
Der Lernalgorithmus nutzt den Ansatz des "Teile und Herrsche" und reduziert die inhärente Varianz einer einzelnen Instanz des Modells durch Bootstrapping. Das "Ensembling" einer Gruppe schwächerer Klassifikatoren steigert daher die Leistung und der daraus resultierende aggregierte Klassifikator ist ein stärkeres Modell.
Der Random Decision Forest ist eine Abwandlung des Bagging - Bootstrap Aggregation, die 2001 von Leo Breiman vorgeschlagen wurde - und stellt eine große Sammlung von Bäumen mit Dekorrelation zu zufällig ausgewählten Merkmalen zusammen[1]. Die ``Anzahl der Bäume``, aus denen der Wald besteht, hängt mit der Varianz des Modells zusammen, während die ``Tiefe des Baums`` oder die ``maximale Anzahl der Knoten, aus denen jeder Baum besteht``, mit der irreduziblen Verzerrung des Modells zusammenhängt.

RF hat eine Reihe von Vorteilen: Er ist sehr schnell zu implementieren und auszuführen (läuft effizient auf großen Datensätzen), einer der genauesten Lernalgorithmen und resistent gegen Überanpassung und Ausreißer[2]. Die Leistung von RF ist ähnlich, aber robuster als die von Gradient Boosted Decision Trees (GBDT), einer anderen Unterklasse von Baum-Ensemble-Methoden. Da RF außerdem weniger Hyperparameter als GBDT hat, ist es einfacher zu trainieren und abzustimmen. Infolgedessen ist RF sehr beliebt und wird in verschiedenen Sprachen wie R und SAS sowie in vielen Python-Paketen wie Scikit-Learn und TensorFlow unterstützt.
TensorForest-Schätzer: Kompatibilität und Verwendung
TensorFlow hat kürzlich Unterstützung für RF in die beigetragene Codebasis - tf.contrib - durch ein Modul namens tensor_forest aufgenommen (definiert in https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/tensor_forest/__init__.py, beachten Sie, dass der Link zu tensor_forest auf der offiziellen TensorFlow-Website den Benutzer auf den Zweig mit der neuesten Version und nicht auf den Master-Zweig verweist). Es gibt signifikante Änderungen an tensor_forest in Version 1.3.0 gegenüber Version 1.2.0 und die zu besprechende Codestruktur und Parameter entsprechen der Version 1.2.0.
TensorForest Struktur und Implementierung
Die folgenden Module sollten importiert werden, um tensor_forest zu verwenden:
- von tensorflow.contrib.learn.python.learn import metric_spec
- von tensorflow.contrib.learn.python.learn.estimators import estimator
- von tensorflow.contrib.tensor_forest.client import eval_metrics
- von tensorflow.contrib.tensor_forest.client import random_forest
- von tensorflow.contrib.tensor_forest.python import tensor_forest
Der erste Schritt zur Ausführung von RF in TensorFlow ist die Konstruktion des Modells. Um einen RF-Schätzer zu erstellen, legen Sie zunächst die Hyperparameter des RF wie folgt fest:
hparams = tensor_forest.ForestHParams(num_classes=NUM_CLASSES,num_features=NUM_FEATURES,num_trees=NUM_TREES,max_nodes=MAX_NODES,min_split_samples=MIN_NODE_SIZE).fill()Jeder der oben genannten Hyperparameter für den Tensorwald wird im Folgenden beschrieben:
``Anzahl_Klassen``: Die Anzahl der möglichen Klassen für Etiketten
Anzahl_Features``: Die Anzahl der Merkmale. Entweder ``num_splits_to_consider`` oder ``num_features`` sollte
gesetzt werden; nach Angaben der Programmierer von tensor_forest ist das Modell genauer
wenn ``Anzahl_Splits_zu_berücksichtigen`` == ``Anzahl_Merkmale``[4].
Anzahl_Bäume": Die Anzahl der Bäume, die für die Ermittlung des Modus [für die Klassifizierung] oder des Mittelwertes [für die
Regression] von Vorhersagen. Bäume sind "notorisch verrauscht", so dass sie "stark von der Mittelwertbildung profitieren"[5]. Je mehr Bäume der Wald umfasst, desto geringer ist die Varianz des Modells und desto genauer sind die Ergebnisse. Es besteht jedoch ein Kompromiss zwischen Ausgabeleistung und Ausführungsgeschwindigkeit. Die Verwendung einer großen Anzahl von Bäumen bedeutet einen höheren Rechenaufwand und könnte den Code erheblich verlangsamen. In der Regel erreicht die Modellleistung nach einer bestimmten Anzahl von Bäumen ein Plateau und die Verbesserung ist vernachlässigbar[6].
Ich baue gerne einen Wald mit fünf Bäumen, um meinen Code zu Debugging-Zwecken zu testen, einen Wald mit 100 Bäumen, um ein erstes Gefühl für Genauigkeit, Präzision, Recall, Auc usw. zu bekommen, und einen Wald mit 500 Bäumen für ein endgültiges Modell, das keine größeren Anpassungen benötigt. Im Allgemeinen führt die Verwendung eines Modells mit 1000 Bäumen nicht zu einer signifikanten Leistungssteigerung gegenüber einem Wald mit 500 Bäumen.
*Standard: 100
Die folgenden zwei Hyperparameter bestimmen die Baumtiefe in einem Wald. Eine Begrenzung der Baumtiefe bringt außer einer Begrenzung der Rechenzeit keinen zusätzlichen Nutzen und wird nicht empfohlen[7]. Größere Tiefe bedeutet geringere Verzerrung. Wenn Bäume "ausreichend tief wachsen, [haben sie] eine relativ geringe Verzerrung"[8].
``max_nodes``: Die maximale Anzahl von Knoten, die für jeden Baum erlaubt ist. Eine größere Anzahl von ``max_nodes``
ermöglicht tiefere Bäume.
*Standard: 10000.
``min_split_samples``: "Die Mindestanzahl von Stichproben, die erforderlich ist, um einen internen Knoten aufzuteilen" gemäß
SKlearn[9]. ``min_split_samples`` ist mit der minimalen Knotengröße verbunden. Je weniger Stichproben zur Aufteilung eines Knotens erforderlich sind, desto tiefer kann der Baum wachsen.
*Standard: 5

Bestimmen Sie dann den Typ des Graphen, der mit RF verwendet werden soll; es gibt zwei Arten von Graphen: Der Standard-RF-Graph [``RandomForestGraphs``] und der Trainingsverlust-Graph [``TrainingLossForest``][11]. Für den Prior kann der Benutzer die positiven Instanzen hochgewichten, normalerweise für unausgewogene Datensätze, indem er einen Gewichtsvektor angibt.
[Anmerkung: ``SKCompat`` ist der Scikit-Learn Wrapper für TensorFlow[12]. Model_dir" sollte ein Verzeichnis sein, in dem die RF und die Log-Datei für die Tensorboard-Visualisierung gespeichert werden].
Wenn das RF-Diagramm ausgewählt ist:
Um ein Aufgewicht anzugeben:
graph_builder_class = tensor_forest.RandomForestGraphs
est = estimator.SKCompat(random_forest.TensorForestEstimator(
params,
graph_builder_class=graph_builder_class,
model_dir=MODEL_DIRECTORY,
gewichte_name='gewichte'))
Oder behalten Sie die Standardeinstellung der 1:1-Gewichtung von positiven und negativen Datenpunkten bei:
graph_builder_class = tensor_forest.RandomForestGraphs
est = estimator.SKCompat(random_forest.TensorForestEstimator(
params,
graph_builder_class=graph_builder_class,
model_dir=MODEL_DIRECTORY))
Im Falle des Trainingsverlustwaldes wird der aus der Standardverlustfunktion [``log_loss``] oder einer spezifizierten Verlustfunktion berechnete Trainingsverlust zur Anpassung der Gewichte verwendet[13].
Verwenden Sie die Standardfunktion ``log loss`` als Verlustfunktion:
graph_builder_class = tensor_forest.TrainingLossForest
Oder geben Sie eine Verlustfunktion an, die im Trainingsverlustdiagramm verwendet werden soll[14]:
from tensorflow.contrib.losses.python.losses import loss_ops
# gültige Verlustfunktionen sind:
#["absolute_difference",
#"add_loss",
#"cosine_distance",
#"compute_weighted_loss",
#"get_losses",
#"get_regularization_losses",
#"get_total_loss",
#"hinge_loss",
#"log_loss",
#"mean_pairwise_squared_error",
#"mean_squared_error",
#"sigmoid_cross_entropy",
#"softmax_cross_entropy",
#sparse_softmax_cross_entropy"]
def loss_fn(val, pred):
_loss = loss_ops.hinge_lss(val, pred)
Rückgabe _Verlust
def _build_graph(params, **kwargs):
return tensor_forest.TrainingLossForest(params,
loss_fn=_loss_fn, **kwargs)
graph_builder_class = _build_graph
Schließlich wird der RF-Schätzer mit den zuvor festgelegten Hyperparametern und dem Graphen konstruiert. est= estimator.SKCompat(random_forest.TensorForestEstimator(
hparams,
graph_builder_class=graph_builder_class,
model_dir=MODEL_DIRECTORY))
Nachdem das RF konstruiert wurde, passen Sie das Modell mit der Methode ``fit`` an die Trainingsdaten an.
Für RF-Diagramm mit angegebener Gewichtung*:
est.fit(x={‘x’:x_train, ‘weights’:train_weights},
y={‘y’:y_train},
batch_size=BATCH_SIZE,
max_steps=MAX_STEPS)
*Hinweis: `Gewichte` sollte derselbe Schlüssel sein wie der, der zuvor an ``TensorForestEstimator`` übergeben wurde.
train_weights" sollte Dimension sein: (Anzahl der Stichproben, )
Für Standard 1:1 Gewichtung oder Trainingsverlust Wald:
est.fit(x=x_train, y=y_train
batch_size=BATCH_SIZE,
max_steps=MAX_STEPS)
Um die vom Modell ausgegebenen Ergebnisse zu bewerten, müssen Sie die gewünschten Metriken identifizieren und sie an die Funktion ``evaluate`` übergeben[15].
# andere Metriken umfassen:
# true positives: tf.contrib.metrics.streaming_true_positives
# wahre Negative: tf.contrib.metrics.streaming_true_negatives
# Falsch positive Ergebnisse: tf.contrib.metrics.streaming_false_positives
# Falsche Negative: tf.contrib.metrics.streaming_false_negatives
# auc: tf.contrib.metrics.streaming_auc
# r2: eval_metrics.get_metric('r2')
# Genauigkeit: eval_metrics.get_metric('Genauigkeit')
# Rückruf: eval_metrics.get_metric('Rückruf')
metric = {‘accuracy’:metric_spec.MetricSpec(eval_metris.get_metric(‘accuracy’),
prediction_key=eval_metrics.get_prediction_key('accuracy')}
Wenn Aufgewicht gegeben ist:
model_stats = est.score(x={‘x’:x_test, ‘weights’:test_weights},
y={‘y’:y_test},
batch_size=BATCH_SIZE,
max_steps=MAX_STEPS,
metrics=metric)
for metric in model_stats:
print('%s: %s' % (metric, model_stats[metric])
Für Standardgewichtung und Trainingsverlust Wald:
model_stats = est.score(x=x_test, y=y_test
batch_size=BATCH_SIZE,
max_steps=MAX_STEPS,
metrics=metric)
for metric in model_stats:
print('%s: %0.4f' % (metric, model_stats[metric])
Für das vorhergesagte Label und die Wahrscheinlichkeit jeder Klasse für jede Dateninstanz:
[Anmerkung: ``predicted_prob`` und ``predicted_class`` sind Numpy-Arrays, die die Reihenfolge der ursprünglichen Eingabe beibehalten]
Aufgewicht angegeben:
predictions = dict(est.predict({‘x’:x_test, ‘weights’:test_weights}))
predicted_prob = predictions[eval_metrics.INFERENCE_PROB_NAME]
predicted_class = predictions[eval_metrics.INFERENCE_PRED_NAME]
Standardgewichtung und Trainingsverlustwald:
Vorhersagen = dict(est.predict(x=x_test))
predicted_prob = predictions[eval_metrics.INFERENCE_PROB_NAME]
predicted_class = predictions[eval_metrics.INFERENCE_PRED_NAME]
Schließlich starten Sie Tensorboard über Terminal, um den Trainingsprozess und den TensorFlow-Graphen zu visualisieren:
Das Verzeichnis, das zuvor an ``model_dir`` übergeben wurde, sollte angegeben werden.
$ tensorboard --logdir="./"
Öffnen Sie http://localhost:6006/ oder den Link aus dem obigen Befehl im Browser, um das Tensorboard anzuzeigen.

Vergleich von TensorFlow und Scikit-Learn für Random Forest Modelle
Derzeit sind TensorFlow und scikit-learn beides sehr beliebte Pakete, die jeweils von Expertenteams entwickelt und gepflegt werden. Es gibt unzählige Tutorials zur Verwendung des Codes online und in gedruckter Form, die die meisten Algorithmen des maschinellen Lernens abdecken. Diese beiden Module sind jedoch nicht auf dieselben Aufgaben ausgerichtet.
scikit-learn

Scikit wird seit langem als "de facto offizielles Python-Framework für allgemeines maschinelles Lernen"[17] angesehen. Scikit bietet eine umfassende Codebasis von Algorithmen für maschinelles Lernen, die zu verschiedenen Kategorien gehören: Klassifizierung, Regression, Clustering, Dimensionalitätsreduktion usw.[18]. Diese gut verpackten Algorithmen ermöglichen den Nutzern einen einfachen und schnellen Zugang zur Analyse der Datenmenge. So enthält sklearn beispielsweise ein RF-Modul, das mit nur wenigen Zeilen auf Datensätze angewendet werden kann:

Neben seiner mühelosen Bedienbarkeit und seiner standardisierten API ist scikit-learn auch außerordentlich gut dokumentiert. Für jede Bibliothek gibt es Seiten, die nicht nur die Schnittstelle, die Eingabeparameter und das Ausgabeformat detailliert beschreiben, sondern auch die Verwendung des Codes mit sorgfältig konstruierten Beispielen demonstrieren. Zur Veranschaulichung wird wieder das RF-Modul von Sklearn verwendet:
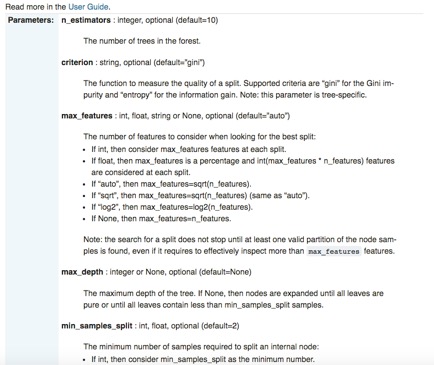

Während scikit-learn zahlreiche herausragende Vorteile hat, wie z. B. "syntaktische Kürze"[22], hat es ein besonderes Manko: sklearn unterstützt keine GPU und wird dies auch in naher Zukunft nicht tun[23]. "Die GPU-Unterstützung wird viele Software-Abhängigkeiten und plattformspezifische Probleme mit sich bringen. [...] Abgesehen von neuronalen Netzen spielen GPUs heute keine große Rolle beim maschinellen Lernen", heißt es auf der offiziellen Website von sklearn. Auf der anderen Seite eignet sich TensorFlow durch seine native Unterstützung für GPUs besonders gut für Deep Learning.
TensorFlow
Die Stärke von TensorFlow zeigt sich in seiner Skalierbarkeit, um "tiefe neuronale Netze auf GPUs [und] möglicherweise auf Clustern mit mehreren Maschinen zu trainieren"[24], und in der großen Freiheit, die den Nutzern bei der Zusammenstellung ihrer eigenen Deep-Learning-Algorithmen gewährt wird. Die Benutzer legen nicht nur fest, welche Art von Modell verwendet wird, sondern auch, wie es mit Hilfe der vom Framework bereitgestellten Primitive implementiert wird[25]. Sie definieren genau, "wie [...] Daten transformiert werden sollen [und] welche Verlustfunktion das Modell optimieren soll"[26]. Darüber hinaus ist TensorFlow sehr flexibel und portabel; es ist auf einer Vielzahl von Plattformen - einschließlich Ubuntu, Mac OS X, Windows, Android, iOS - und einer Vielzahl von Sprachen, wie Python, Java, C, Go, verfügbar[27]. Obwohl TensorFlow durch seine Skalierbarkeit und Integrierbarkeit besonders attraktiv erscheint, erschweren die komplizierte Codestruktur, mysteriöse Fehlermeldungen und in einigen Fällen schlecht dokumentierte Module den Debugging-Prozess. Daher ist die Verwendung von TensorFlow für die "meisten praktischen Aufgaben des maschinellen Lernens" wahrscheinlich zu viel des Guten[28].
Einführung in Scikit Flow: Die Brücke zwischen TensorFlow und Scikit-Learn
[https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/learn/python/learn]
Scikit Flow (SKFlow) wurde als Lösung für das scikit-TensorFlow-Dilemma eingeführt: Es nutzt die "Modellierungskraft von TensorFlow, indem es die syntaktische Prägnanz von scikit-learn kanalisiert"[29]. SKFlow ist ein offizielles Projekt, das von Google entwickelt wurde und einen vereinfachten High-Level-Wrapper für TensorFlow bietet[30].
Ein dreischichtiges neuronales Netz mit 10, 20 bzw. 10 versteckten Einheiten kann mit vier Zeilen in SKFlow implementiert werden:

Oder die Erstellung eines benutzerdefinierten Modells mit SKFlow mit etwa 10 Zeilen Code:
