

Die Definition von künstlicher Intelligenz (KI) ist eine komplexe Aufgabe, die oft von wechselnden Perspektiven abhängt. Definitionen, die auf Zielen oder Aufgaben basieren, können sich mit dem technologischen Fortschritt ändern. So waren beispielsweise schachspielende Systeme ein Schwerpunkt der frühen KI-Forschung, bis IBMs Deep Blue 1997 den Großmeister Gary Kasparow besiegte und sich die Wahrnehmung des Schachspiels von der Notwendigkeit von Intelligenz zu Brute-Force-Techniken verschob.
Andererseits verstricken sich KI-Definitionen, die sich auf prozedurale oder strukturelle Gründe konzentrieren, oft in grundlegend unlösbare philosophische Fragen über Geist, Emergenz und Bewusstsein. Diese Definitionen tragen nicht zu unserem Verständnis der Konstruktion intelligenter Systeme bei und helfen uns auch nicht bei der Beschreibung von Systemen, die wir bereits entwickelt haben.
Der Turing-Test - ein Maß für die Intelligenz von Maschinen

Mit dem Turing-Test, der oft als Test für die Intelligenz von Maschinen angesehen wird, wollte Alan Turing der Frage nach der Intelligenz aus dem Weg gehen. Er betonte die semantische Unbestimmtheit von Intelligenz und konzentrierte sich darauf, was Maschinen tun können, und nicht darauf, wie wir sie bezeichnen.
"Die ursprüngliche Frage 'Können Maschinen denken?' halte ich für zu bedeutungslos, um eine Diskussion zu verdienen. Dennoch glaube ich, dass sich am Ende des Jahrhunderts der Wortgebrauch und die allgemeine gebildete Meinung so sehr verändert haben werden, dass man von denkenden Maschinen sprechen kann, ohne zu erwarten, dass man widersprochen wird." - Alan Turing
Letztlich handelt es sich um eine Frage der Konvention, die sich nicht wesentlich von der Diskussion darüber unterscheidet, ob wir U-Boote als schwimmend oder Flugzeuge als fliegend bezeichnen sollten. Für Turing waren die Grenzen dessen, wozu Maschinen fähig sind, wirklich wichtig, nicht wie wir diese Fähigkeiten bezeichnen.
Messung des menschenähnlichen Denkens in der KI
Wenn man also wissen will, ob Maschinen wie Menschen denken können, sollte man am besten messen, wie gut die Maschine anderen Menschen vorgaukeln kann, dass sie wie Menschen denkt. In Anlehnung an Turing und die Definition der Organisatoren des ersten Workshops über künstliche Intelligenz im Jahr 1956 gehen wir ebenfalls davon aus, dass "jeder Aspekt des Lernens oder jedes andere Merkmal der Intelligenz im Prinzip so genau beschrieben werden kann, dass eine Maschine dazu gebracht werden kann, ihn zu simulieren".
Um eine menschenähnliche Leistung oder ein menschenähnliches Verhalten bei einer bestimmten Aufgabe zu erreichen, sollte die KI in der Lage sein, diese mit einem bemerkenswerten Maß an Präzision zu simulieren. Der berühmte Turing-Test wurde entwickelt, um diese Fähigkeit zu beurteilen, indem bewertet wurde, wie effektiv ein Computer oder eine Maschine einen Beobachter durch eine unstrukturierte Unterhaltung täuschen kann. Der ursprüngliche Test von Turing verlangte sogar, dass die Maschine eine weibliche Identität überzeugend darstellen sollte.
Bewertung des Verständnisses von KI auf menschlicher Ebene
In den letzten Jahren haben bedeutende Fortschritte bei den Techniken des maschinellen Lernens in Verbindung mit der Fülle an umfangreichen Trainingsdaten Algorithmen in die Lage versetzt, sich mit minimalem Verständnis zu unterhalten. Darüber hinaus tragen scheinbar unbedeutende Taktiken, wie das absichtliche Einfügen von zufälligen Rechtschreib- und Grammatikfehlern, dazu bei, dass Algorithmen immer überzeugender als virtuelle Menschen wirken, obwohl ihnen echte Intelligenz fehlt.
Neuartige Ansätze zur Bewertung des Verständnisses auf menschlicher Ebene, wie die Winograd-Schemata, schlagen vor, eine Maschine nach ihrem Wissen über die Welt, die Verwendung von Objekten und die Möglichkeiten zu befragen, die von Menschen allgemein verstanden werden. Wenn wir zum Beispiel die Frage stellen würden: "Warum passte die Trophäe nicht in das Regal? Weil sie zu groß war. Was war zu groß?" würde jeder Mensch sofort feststellen, dass die Trophäe das übergroße Element ist. Mit einer einfachen Ersetzung - "Die Trophäe passte nicht in das Regal, weil sie zu klein war. Was war zu klein?" - fragen wir nach der Unzulänglichkeit der Größe.
Bei diesem Szenario liegt die Antwort eindeutig im Regal. Dieser Test taucht mit hoher Präzision in die Tiefen des maschinellen Wissens über die Welt ein. Einfaches Data Mining allein kann keine Antwort liefern. Diese Definition setzt voraus, dass eine KI in der Lage ist, jede Facette menschlichen Verhaltens zu emulieren, was einen bedeutenden Unterschied zu KI-Systemen darstellt, die speziell darauf ausgelegt sind, Intelligenz für bestimmte Aufgaben zu demonstrieren.
Unterscheidung der KI-Typen und ihrer Lernmethoden
Künstliche allgemeine Intelligenz (AGI)
Künstliche allgemeine Intelligenz (Artificial General Intelligence, AGI), auch bekannt als allgemeine KI, ist das am häufigsten diskutierte Konzept, wenn es um KI geht. Er umfasst die Systeme, die futuristische Vorstellungen von der Herrschaft von Robotern über die Welt hervorrufen und unsere kollektive Vorstellungskraft in Literatur und Film beflügeln.
Spezifische oder angewandte AI
Der Großteil der Forschung in diesem Bereich konzentriert sich auf spezifische oder angewandte KI-Systeme. Diese umfassen eine breite Palette von Anwendungen, von der Spracherkennung und den Bildverarbeitungssystemen von Google und Facebook bis hin zu der von unserem Team bei Vectra AI entwickelten KI für die Cybersicherheit.
Angewandte Systeme nutzen in der Regel ein breites Spektrum an Algorithmen. Die meisten Algorithmen sind so konzipiert, dass sie mit der Zeit lernen und sich weiterentwickeln und ihre Leistung optimieren, wenn sie Zugang zu neuen Daten erhalten. Die Fähigkeit, sich als Reaktion auf neue Eingaben anzupassen und zu lernen, definiert den Bereich des maschinellen Lernens. Es ist jedoch wichtig zu wissen, dass nicht alle KI-Systeme diese Fähigkeit benötigen. Einige KI-Systeme können mit Algorithmen arbeiten, die nicht auf Lernen angewiesen sind, wie z. B. die Strategie von Deep Blue beim Schachspielen.
Allerdings beschränken sich diese Vorgänge in der Regel auf genau definierte Umgebungen und Problembereiche. Tatsächlich stützen sich Expertensysteme, eine Säule der klassischen KI (GOFAI), in hohem Maße auf vorprogrammiertes, regelbasiertes Wissen anstelle von Lernen. Es wird davon ausgegangen, dass AGI und die Mehrzahl der häufig angewandten KI-Aufgaben eine Form des maschinellen Lernens erfordern.

Die Rolle der Machine Learning
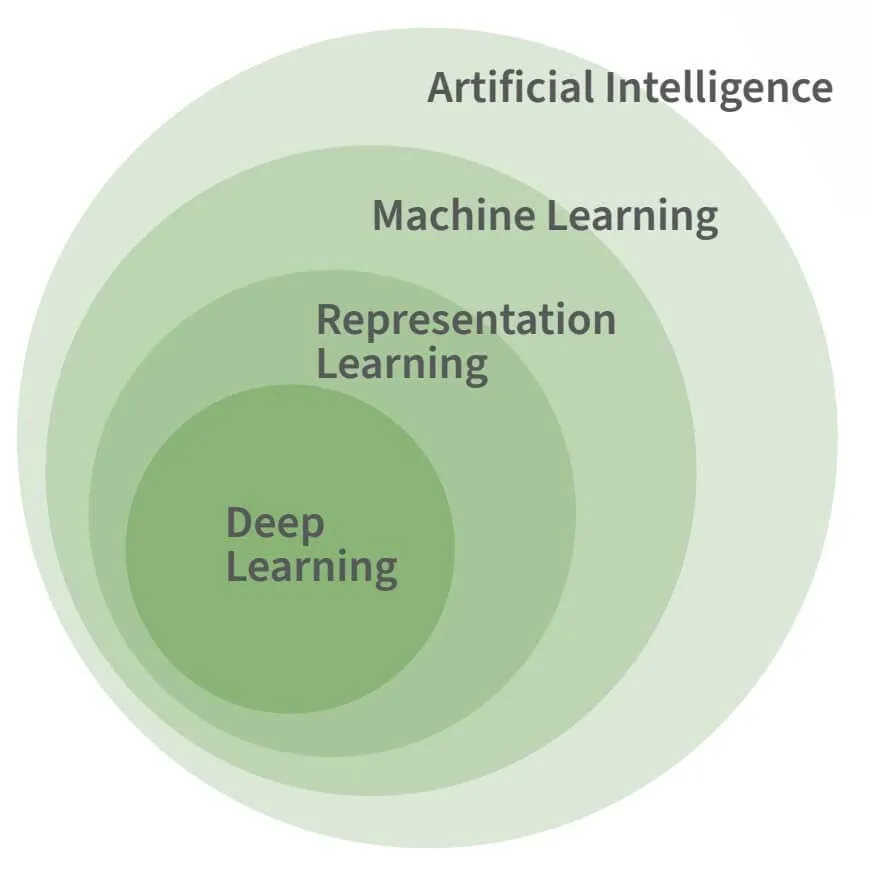
Die obige Abbildung zeigt die Beziehung zwischen KI, maschinellem Lernen und Deep Learning. Deep Learning ist eine spezielle Form des maschinellen Lernens, und obwohl man davon ausgeht, dass maschinelles Lernen für die meisten fortgeschrittenen KI-Aufgaben notwendig ist, ist es für sich genommen kein notwendiges oder definierendes Merkmal von KI.
Das maschinelle Lernen ist notwendig, um die grundlegenden Facetten der menschlichen Intelligenz nachzuahmen, und nicht die Feinheiten. Nehmen wir zum Beispiel das von Allen Newell und Herbert Simon 1955 entwickelte KI-Programm Logic Theorist. Es konnte 38 der anfänglichen 52 Theoreme der Principia Mathematica beweisen, ohne dass dafür ein Lernprozess erforderlich war.
KI, Machine Learning und Deep Learning: Was ist der Unterschied?
Künstliche Intelligenz (KI), maschinelles Lernen (ML) und Deep Learning (DL) werden oft fälschlicherweise für ein und dasselbe gehalten, haben aber jeweils ihre eigene Bedeutung. Wenn wir den Umfang dieser Begriffe verstehen, können wir einen Einblick in die Tools gewinnen, die KI nutzen.
Künstliche Intelligenz (KI)
KI ist ein weit gefasster Begriff, der Systeme umfasst, die in der Lage sind, das Denken zu automatisieren und sich dem menschlichen Verstand anzunähern. Dazu gehören auch Teildisziplinen wie ML, RL und DL. KI kann sich sowohl auf Systeme beziehen, die explizit programmierten Regeln folgen, als auch auf solche, die selbstständig Erkenntnisse aus Daten gewinnen. Die letztere Form, die aus Daten lernt, ist die Grundlage für Technologien wie selbstfahrende Autos und virtuelle Assistenten.
Machine Learning (ML)
ML ist eine Teildisziplin der künstlichen Intelligenz, bei der die Aktionen des Systems aus den Daten gelernt werden und nicht ausdrücklich vom Menschen diktiert werden. Diese Systeme können riesige Datenmengen verarbeiten, um zu lernen, wie sie neue Daten optimal darstellen und auf sie reagieren können.
Video: Machine Learning Grundlagen für Cybersecurity-Fachleute
Representation Learning (RL)
RL, das oft übersehen wird, ist für viele der heute eingesetzten KI-Technologien von entscheidender Bedeutung. Es geht darum, abstrakte Darstellungen aus Daten zu lernen. So werden beispielsweise Bilder in Listen mit konsistenten Zahlen umgewandelt, die das Wesentliche der ursprünglichen Bilder erfassen. Diese Abstraktion ermöglicht es nachgelagerten Systemen, neue Datentypen besser zu verarbeiten.
Deep Learning (DL)
DL baut auf ML und RL auf, indem Hierarchien von Abstraktionen entdeckt werden, die Eingaben auf komplexere Weise darstellen. Nach dem Vorbild des menschlichen Gehirns verwenden DL-Modelle Schichten von Neuronen mit anpassbaren synaptischen Gewichten. Tiefere Schichten im Netzwerk lernen neue abstrakte Repräsentationen, die Aufgaben wie die Kategorisierung von Bildern und die Übersetzung von Texten vereinfachen. Es ist wichtig zu wissen, dass DL zwar für die Lösung bestimmter komplexer Probleme geeignet ist, aber keine Einheitslösung für die Automatisierung von Intelligenz darstellt.
Referenz: "Deep Learning," Goodfellow, Bengio & Courville (2016)
Lerntechniken in AI
Weitaus schwieriger ist die Aufgabe, Programme zu entwickeln, die Sprache erkennen oder Objekte in Bildern finden, obwohl sie von Menschen relativ leicht gelöst werden können. Diese Schwierigkeit rührt daher, dass wir, obwohl es für den Menschen intuitiv einfach ist, keine einfachen Regeln beschreiben können, mit denen wir Phoneme, Buchstaben und Wörter aus akustischen Daten herausfiltern könnten. Das ist derselbe Grund, warum wir nicht einfach die Pixelmerkmale definieren können, die ein Gesicht von einem anderen unterscheiden.

Die Abbildung rechts stammt aus Oliver Selfridges Artikel "Pattern Recognition and Modern Computers" von 1955 und zeigt, dass dieselben Eingaben je nach Kontext zu unterschiedlichen Ergebnissen führen können. Unten sind das H in THE und das A in CAT identische Pixelmengen, aber ihre Interpretation als H oder A hängt von den umgebenden Buchstaben ab und nicht von den Buchstaben selbst.
Aus diesem Grund ist es erfolgreicher, wenn Maschinen lernen können, wie man Probleme löst, anstatt zu versuchen, eine Lösung im Voraus zu definieren.
ML-Algorithmen sind in der Lage, Daten in verschiedene Kategorien einzuteilen. Die beiden Haupttypen des Lernens, überwachtes und unüberwachtes Lernen, spielen bei dieser Fähigkeit eine große Rolle.
Überwachtes Lernen
Beim überwachten Lernen lernt ein Modell mit markierten Daten, so dass es in der Lage ist, die Markierungen für neue Daten vorherzusagen. Beispielsweise kann ein Modell, das mit Katzen- und Hundebildern konfrontiert wird, neue Bilder klassifizieren. Obwohl es gekennzeichnete Trainingsdaten benötigt, kennzeichnet es effektiv neue Datenpunkte.

Unüberwachtes Lernen
Unüberwachtes Lernen hingegen arbeitet mit nicht beschrifteten Daten. Diese Modelle lernen Muster innerhalb der Daten und können bestimmen, wo neue Daten in diese Muster passen. Unüberwachtes Lernen erfordert kein vorheriges Training und eignet sich hervorragend zum Erkennen von Anomalien, hat aber Schwierigkeiten, diese zu benennen.
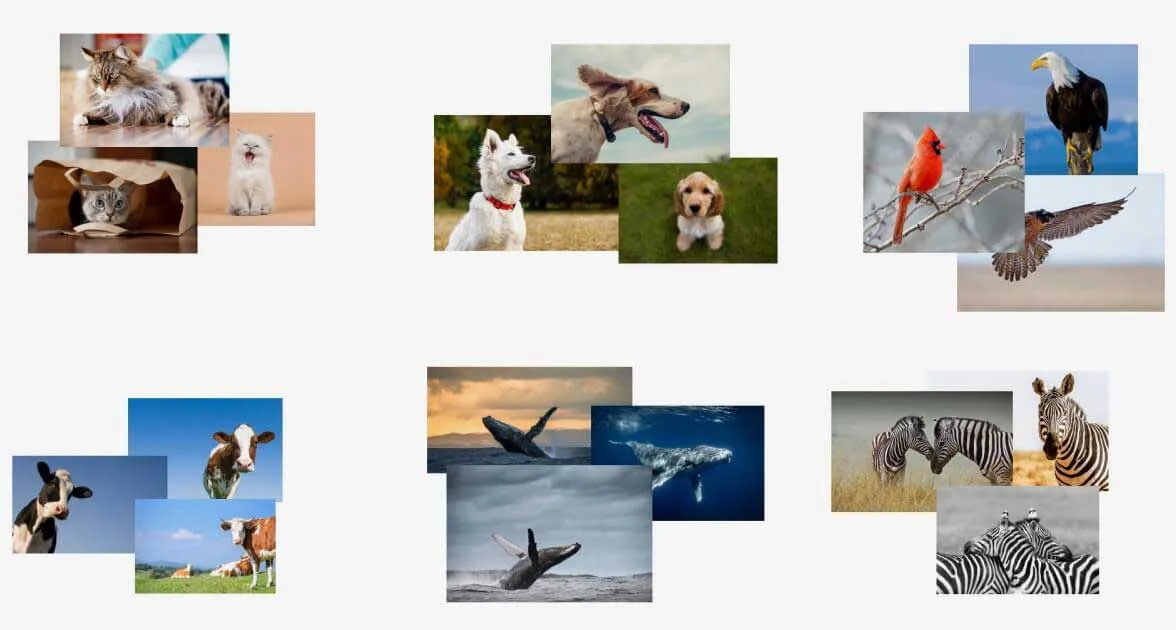
Beide Ansätze bieten eine Reihe von Lernalgorithmen, die durch die Entwicklung neuer Algorithmen durch die Forscher ständig erweitert werden. Algorithmen können auch kombiniert werden, um komplexere Systeme zu schaffen. Für Datenwissenschaftler ist es eine Herausforderung zu wissen, welcher Algorithmus für ein bestimmtes Problem zu verwenden ist. Gibt es einen überlegenen Algorithmus, der jedes Problem lösen kann?

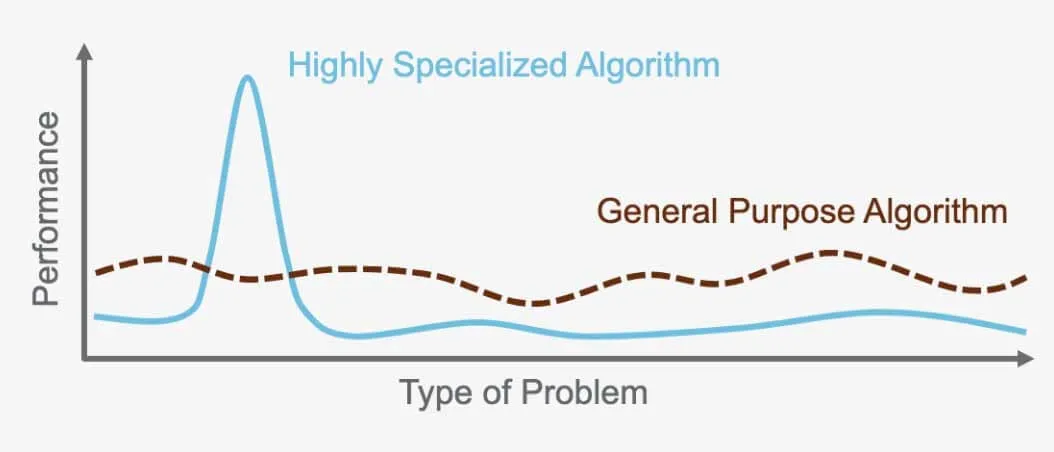
Das "No Free Lunch Theorem": Es gibt keinen universellen Algorithmus
Das "No Free Lunch Theorem" besagt, dass es keinen perfekten Algorithmus gibt, der für jedes Problem besser ist als alle anderen. Stattdessen erfordert jedes Problem einen spezialisierten Algorithmus, der auf seine spezifischen Bedürfnisse zugeschnitten ist. Aus diesem Grund gibt es so viele verschiedene Algorithmen. Ein überwachtes neuronales Netzwerk eignet sich beispielsweise ideal für bestimmte Probleme, während das unüberwachte hierarchische Clustering für andere Probleme am besten geeignet ist. Es ist wichtig, den richtigen Algorithmus für die jeweilige Aufgabe zu wählen, da jeder Algorithmus so konzipiert ist, dass er die Leistung auf der Grundlage des jeweiligen Problems und der verwendeten Daten optimiert.
Der Algorithmus, der für die Bilderkennung in selbstfahrenden Autos verwendet wird, kann zum Beispiel nicht für die Übersetzung zwischen Sprachen eingesetzt werden. Jeder Algorithmus dient einem bestimmten Zweck und ist für das Problem, zu dessen Lösung er entwickelt wurde, und für die Daten, die er verarbeitet, optimiert.
Auswahl des richtigen Algorithmus in der Datenwissenschaft
Die Wahl des richtigen Algorithmus als Datenwissenschaftler ist eine Mischung aus Kunst und Wissenschaft. Durch die Berücksichtigung der Problemstellung und das gründliche Verständnis der Daten kann der Datenwissenschaftler in die richtige Richtung gelenkt werden. Es ist wichtig zu erkennen, dass eine falsche Wahl nicht nur zu suboptimalen, sondern auch zu völlig ungenauen Ergebnissen führen kann. Werfen Sie einen Blick auf das folgende Beispiel:
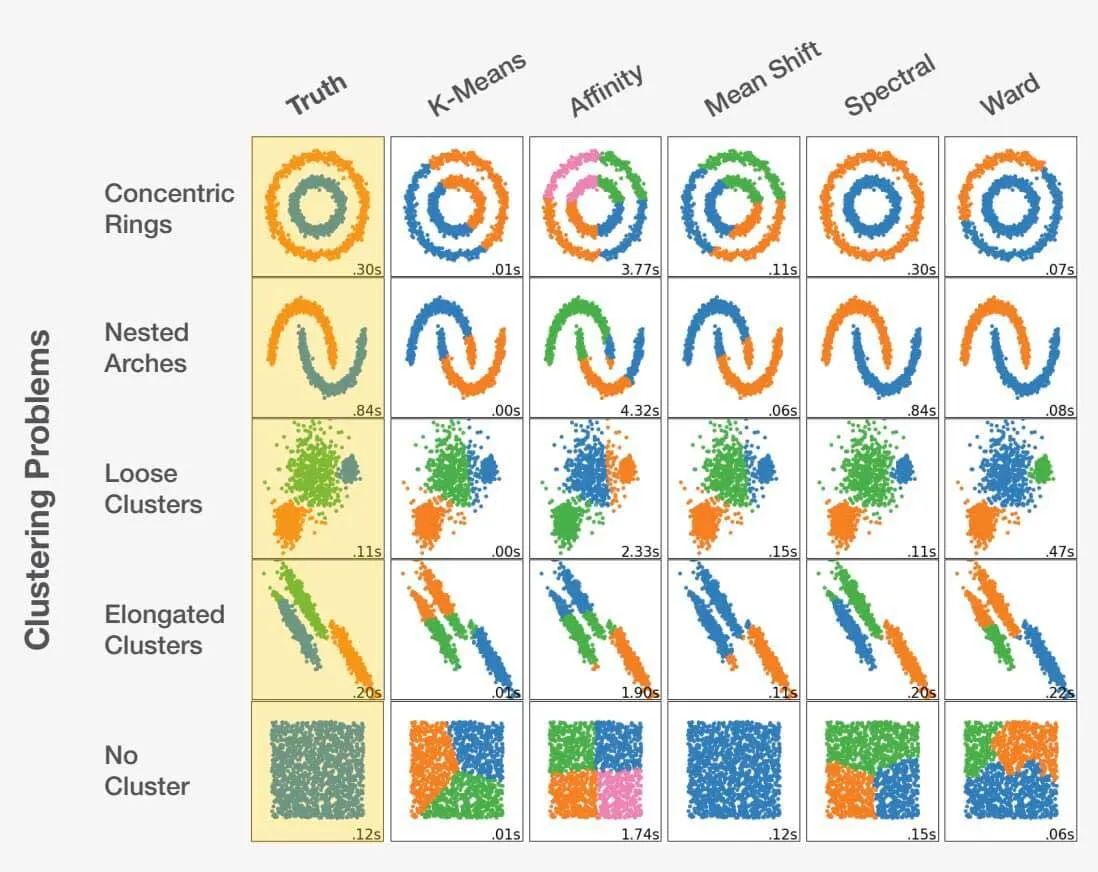
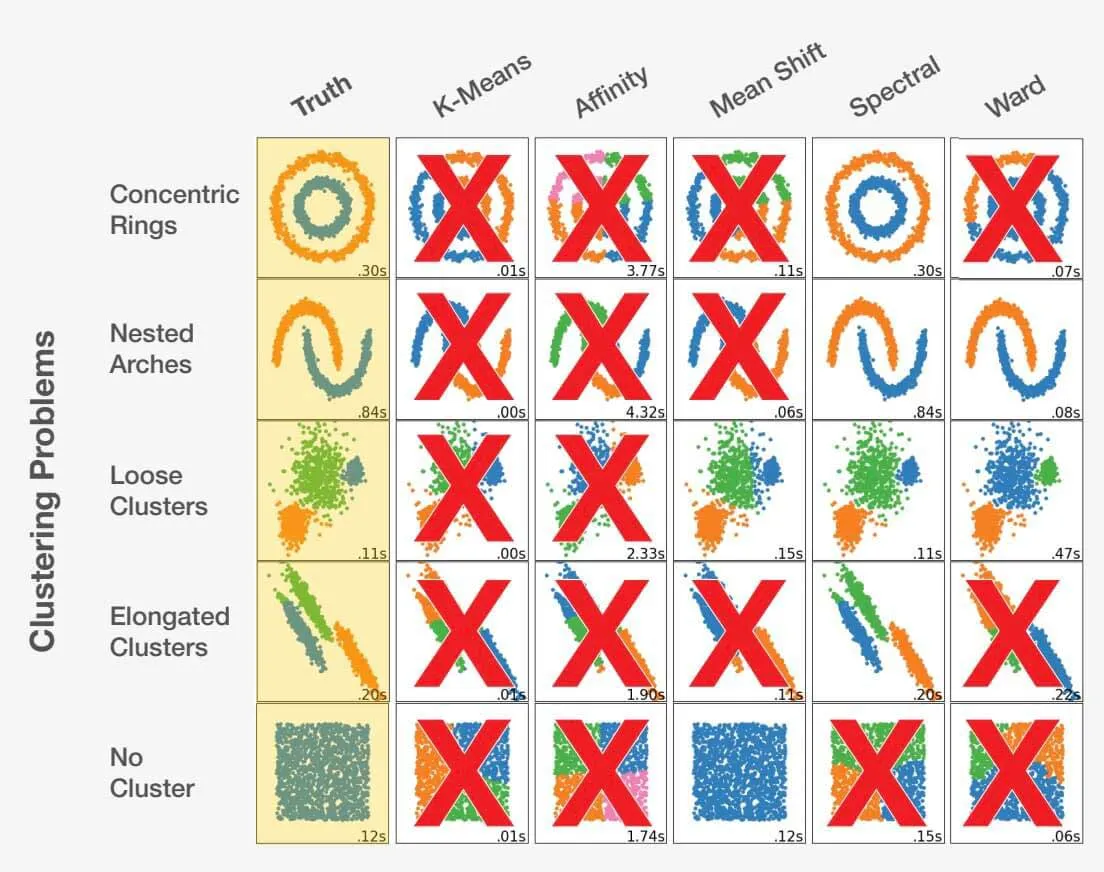
Angepasst von scikit-learn.org.
Die Wahl des richtigen Algorithmus für einen Datensatz kann sich erheblich auf die erzielten Ergebnisse auswirken. Für jedes Problem gibt es einen optimalen Algorithmus, aber noch wichtiger ist, dass bestimmte Entscheidungen zu ungünstigen Ergebnissen führen können. Dies zeigt, wie wichtig es ist, für jedes spezifische Problem den richtigen Ansatz zu wählen.
Wie misst man den Erfolg eines Algorithmus?
Bei der Auswahl des richtigen Modells für Datenwissenschaftler geht es um mehr als nur um Genauigkeit. Genauigkeit ist zwar wichtig, kann aber manchmal die wahre Leistung eines Modells verbergen.

Betrachten wir ein Klassifizierungsproblem mit zwei Bezeichnungen, A und B. Wenn die Wahrscheinlichkeit des Auftretens von Bezeichnung A viel größer ist als die von Bezeichnung B, kann ein Modell eine hohe Genauigkeit erreichen, indem es immer Bezeichnung A wählt. Das bedeutet jedoch, dass es nie etwas korrekt als Bezeichnung B identifizieren wird. Glücklicherweise verfügen Datenwissenschaftler über andere Metriken zur Optimierung und Messung der Effektivität eines Modells.
Eine dieser Metriken ist die Präzision, die misst, wie richtig ein Modell ein bestimmtes Label im Verhältnis zur Gesamtzahl der Schätzungen errät. Datenwissenschaftler, die eine hohe Präzision anstreben, erstellen Modelle, die keine Fehlalarme erzeugen.

Aber die Genauigkeit sagt uns nur einen Teil der Geschichte. Sie sagt nichts darüber aus, ob das Modell Fälle, die für uns wichtig sind, nicht erkennt. Hier kommt der Recall ins Spiel. Recall misst, wie oft ein Modell eine bestimmte Bezeichnung im Verhältnis zu allen Instanzen dieser Bezeichnung korrekt findet. Datenwissenschaftler, die eine hohe Rückrufquote anstreben, erstellen Modelle, die keine wichtigen Instanzen übersehen.

Indem sie sowohl die Präzision als auch den Recall verfolgen und ausgleichen, können Datenwissenschaftler den Erfolg ihrer Modelle effektiv messen und optimieren.