

Kennen Sie den Moment, in dem jemand sagt: "Lasst uns ChatGPT einfach an das SOC anschließen " - und alle nicken, als wäre das völlig in Ordnung? Ja, in diesem Beitrag geht es darum, was nach diesem Moment passiert.
Denn so cool es auch klingt, das Hinzufügen von GenAI zu einem SOC ist keine Zauberei. Es ist chaotisch. Es ist datenintensiv. Und wenn man nicht misst, was wirklich unter der Haube passiert, kann es sein, dass man am Ende nur die Verwirrung automatisiert.
Also haben wir beschlossen, es zu messen.
GenAI in der SOC: coole Idee, harte Realität
Beginnen wir mit dem Offensichtlichen: KI ist in der Sicherheitsbranche derzeit allgegenwärtig.
In jeder SOC-Präsentation ist irgendwo eine große "GenAI-Assistent"-Blase zu sehen. Aber wie diese Assistenten tatsächlich funktionieren, wenn sie mit echten SOC-Workflows konfrontiert werden - das ist der eigentliche Test.
Hier kommt der Vectra MCP Server ins Spiel - der Fluglotse für alle Ihre KI-Agenten.
Es verbindet Ihr LLM (z. B. ChatGPT oder Claude) mit Ihren Sicherheitstools (und deren Daten!) - in diesem Fall mit Vectra AI.
Die MCP orchestriert Anreicherung, Korrelation, Eingrenzung und Kontext, so dass Ihr KI-Agent direkt mit den wichtigen Signalen interagieren kann, anstatt sich in Dashboards zu verlieren.
Und weil wir möchten, dass jeder diese Fähigkeiten nutzen und erleben kann, haben wir 2 MCP-Server veröffentlicht, mit denen Sie jede Vectra-Plattform mit Ihren KI-Workflows verbinden können.
- ☁️ RUX - unser SaaS: http://github.com/vectra-ai-research/vectra-ai-mcp-server
- 🖥️ QUX - unsere On-Prem-Version: http://github.com/vectra-ai-research/vectra-ai-mcp-server-qux
Wenn Sie also schon immer dachten: "Ich wünschte, ich könnte meinen LLM einfach an meinen Sicherheits-Stack anschließen und sehen, was passiert" - jetzt können Sie es. Keine Lizenzprobleme, keine NDAs, einfach einstecken und loslegen.
Wir bei Vectra AI sind fest davon überzeugt, dass GenAI + MCP die Arbeitsweise von SOCs grundlegend verändern wird.
Dies ist keine Idee für die Zukunft - sie findet bereits statt, und wir stellen sicher, dass die Nutzer von Vectra AI für diesen Wandel bestens gerüstet sind.
Das ist auch der Grund, warum wir viel Zeit damit verbringen, mit Kunden, Interessenten und Partnern zu sprechen - um zu verstehen, wie schnell sich diese Technologien weiterentwickeln und was LLM-ready" in einem Live-SOC wirklich bedeutet.
Also haben wir beschlossen, es zu messen.
Denn wenn GenAI die Sicherheitsabläufe umgestalten wird, dann müssen wir absolut sicher sein, dass unsere Plattform, unsere Daten und unsere MCP-Integrationen nahtlos in diese neue Welt passen. Die Messung der Effizienz ist kein Nebenprojekt - so machen wir das SOC zukunftssicher.
Es geht nicht um mehr Daten - es geht um bessere Daten
Wir sagen es ganz offen: GenAI ohne gute Daten ist, als würde man Sherlock Holmes einstellen und ihm die Augen verbinden.
Bei Vectra AI sind die Daten das Unterscheidungsmerkmal. Zwei Dinge machen sie besonders:
- KI-basierte Erkennungen: Sie basieren auf jahrelanger Forschung zum Verhalten von Angreifern, nicht auf Anomalien. Sie sind so konzipiert, dass sie robust sind, d. h. sie bleiben auch dann wirksam, wenn Angreifer ihre Tools wechseln. Jede Erkennung konzentriert sich auf die Absicht und das Verhalten des Angreifers und nicht auf statische Indikatoren, so dass SOC-Teams sicher sein können, dass das, was sie sehen, real und relevant ist.
- Angereicherte Netzwerk-Metadaten: kontextreiche Telemetriedaten, die sich über hybride Umgebungen erstrecken und so strukturiert und korreliert sind, dass sie maschinenlesbar und sofort umsetzbar sind.
Das ist die Art von Daten, die GenAI tatsächlich nutzen kann. Füttern Sie einen LLM damit, und er fängt an, wie ein erfahrener Analytiker zu argumentieren. Füttern Sie es mit rohen Protokollen, und Sie werden eine sehr zuversichtliche Halluzination über DNS erhalten.
Wie kann man einen KI-Analysten überhaupt bewerten?
Es stellt sich heraus, dass man es nicht einfach bitten kann, "böse Jungs schneller zu finden".
Man muss messen, wie es begründet wird. Und wenn Sie mit einem KI-Agenten mit MCP zu tun haben, gibt es hauptsächlich 3 Dinge, die Sie beeinflussen können:
- Das Modell (GPT-5, Claude, Deepseek, usw.)
- Die Aufforderung (wie Sie ihr sagen, dass sie handeln soll - Ton, Struktur, Ziele)
- Der MCP selbst (wie er sich in Ihren Erkennungsstapel einfügt)
Jeder dieser Faktoren kann die Leistung beeinflussen.
Ändern Sie die Eingabeaufforderung geringfügig, und plötzlich vergisst Ihr "selbstbewusster" KI-Analyst, wie man "PowerShell" buchstabiert.
Ändert man das Modell, verdoppelt sich die Latenzzeit.
Ändern Sie die MCP-Integration, und die Hälfte Ihres Kontexts verschwindet.
Deshalb haben wir eine wiederholbare Testumgebung aufgebaut - mit automatischer Auswertung, echten SOC-Szenarien und einer Prise brutaler Ehrlichkeit.
Die Testumgebung (auch bekannt als "wir haben es tatsächlich ausprobiert")
Für den ersten Durchlauf haben wir die Dinge absichtlich einfach gehalten: Tier-1-Aufgaben, leichtes Reasoning (maximal zwei Sprünge), keine ausgefallene Multi-Agenten-Choreographie.
Der Stapel sah wie folgt aus:
- n8n für schnelles Prototyping und Automatisierung
- Vectra QUX MCP-Server um auf die Daten zuzugreifen und die Plattform zu betreiben.
- Eine minimale SOC-Eingabeaufforderung (im Wesentlichen: "Du bist ein KI-Analyst. Hilf mit. Wenn du es nicht weißt, sag es.")
- Bewertung mit Hilfe eines LLM Vergleich der erwarteten mit den tatsächlichen Antworten
Aber dies war kein Spielzeugexperiment. Wir haben 28 echte SOC-Aufgaben getestet, mit denen Analysten tagtäglich konfrontiert werden. Dinge wie:
- Auflistung von Hosts mit hohem oder kritischem Status
- Abrufen von Erkennungen für bestimmte Endpunkte (piper-desktop, deacon-desktop usw.)
- Überprüfung auf Command-and-Control-Erkennungen, die an IPs oder Domänen gebunden sind
- Finden von Exfiltration über 1 GB
- Markierung und Löschung von Host-Artefakten
- Suche nach Konten in Quadranten mit "hohem" oder "kritischem" Risiko
- Suche nach "Admin"-Konten, die am EntraID-Betrieb beteiligt sind
- Abfrage von Erkennungen mit bestimmten JA3-Fingerabdrücken
- Zuweisung von Analysten zu Hosts oder Erkennungen
Im Grunde alles, was ein Tier-1- oder Tier-2-SOC-Analyst an einem geschäftigen Dienstagmorgen anfassen würde.
Jeder Durchlauf wurde hinsichtlich Korrektheit, Geschwindigkeit, Token-Verwendung und Werkzeugaktivität bewertet - alles auf einer Skala von 1-5.
Was macht einen guten GenAI-Agenten aus?
Bei der Bewertung von GenAI in einem SOC geht es nicht darum, welches Modell intelligenter klingt. Es geht darum, wie effizient es denkt, handelt und lernt. Ein guter KI-Agent verhält sich wie ein scharfer Analytiker - er findet nicht nur die richtige Antwort, sondern auch effizient. Worauf Sie achten sollten:
- Effiziente Verwendung von Token. Je weniger Wörter zur Argumentation benötigt werden, desto besser. Langatmige Modelle verschwenden Rechen- und Kontextraum.
- Intelligente Werkzeugaufrufe. Wenn ein Modell immer wieder dasselbe Werkzeug aufruft, sagt es im Grunde: "Lass es mich noch einmal versuchen." Die besten Modelle wissen, wann und wie sie ein Werkzeug einsetzen müssen - minimales Ausprobieren, maximale Präzision.
- Geschwindigkeit ohne Schlamperei. Schnell ist gut, aber nur, wenn die Genauigkeit stimmt. Das ideale Modell bietet ein Gleichgewicht zwischen Reaktionsfähigkeit und Argumentationstiefe.
Kurz gesagt: Ihr bester KI-Analyst redet nicht nur - er denkt effizient.
Hier ist, was wir gefunden haben:

Höhepunkte und praktische Erkenntnisse
- Der GPT-5 überzeugt durch Genauigkeit und Argumentationstiefe, ist aber langsam und teuer. Verwenden Sie es, wenn Präzision wichtiger ist als Geschwindigkeit.
- Claude Sonnet 4.5 bietet die beste Gesamtbilanz: Genauigkeit, Geschwindigkeit und Effizienz. Ideal für Produktions-SOCs.
- Claude Haiku 4.5 eignet sich perfekt für eine schnelle Triage: schnell, billig und "gut genug" für Entscheidungen in erster Linie.
- Deepseek 3.1 ist der Preis-Leistungs-Champion: beeindruckende Leistung zu einem Bruchteil des Preises.
- Grok Code Fast 1 eignet sich für werkzeugintensive Workflows (Automatisierung, Anreicherung usw.), aber achten Sie auf Ihre Token-Rechnung.
- GPT-4.1... sagen wir einfach, es wird nicht zu einer weiteren Schicht eingeladen.
Und weil jeder gute Artikel Grafiken braucht - hier sind einige:
Vergleich der Korrektheitspunkte

GPT-5 ist technisch gesehen der Gewinner mit 4,32/5, aber mal ehrlich? Claude Sonnet 4.5 und Deepseek 3.1 liegen mit 4,11 praktisch gleichauf und Sie werden den Unterschied wahrscheinlich nicht bemerken. Der eigentliche Knackpunkt? GPT 4.1 stürzt mit 2,61/5 völlig ab. Igitt. Verwenden Sie diese Version nicht für Sicherheitsaufgaben.
Ausführungszeit
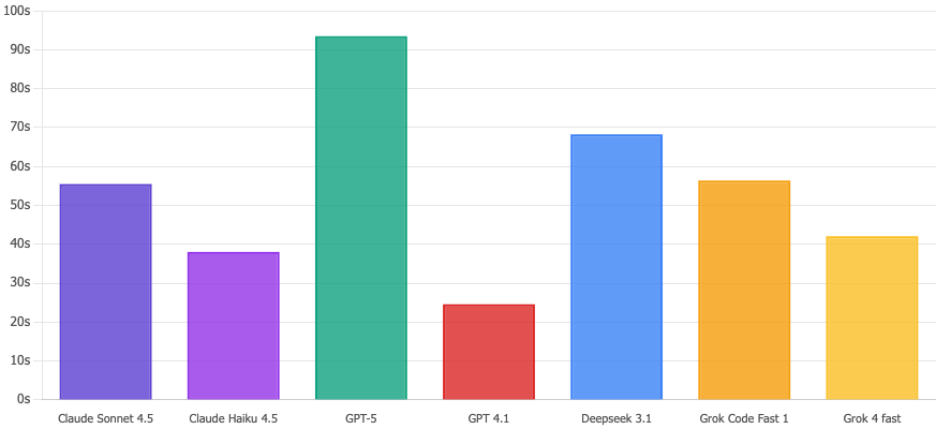
Claude Haiku 4.5 durchläuft diese Abfragen in 38 Sekunden. Währenddessen spaziert GPT-5 gemächlich in 93 Sekunden durch - buchstäblich 2,5x langsamer. Wenn es einen potenziellen Sicherheitsvorfall gibt, fühlen sich diese zusätzlichen Sekunden wie eine Ewigkeit an. Haiku schafft das.
Matrix des Wertangebots
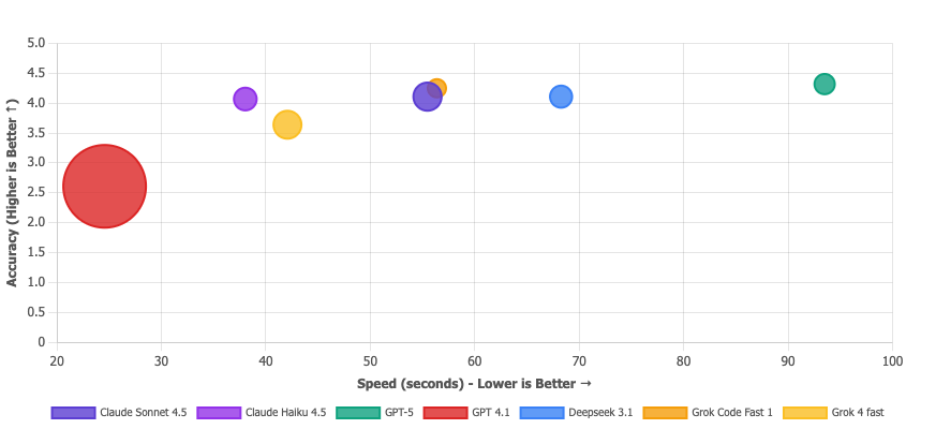
Größere Blase = weniger verbrauchte Token. Die Blase von GPT 4.1 ist riesig, aber das ist kein Flex - das ist so, als würde man sagen: "Ich habe den Test superschnell beendet", obwohl man ihn nicht bestanden hat. Billig und falsch ist kein Wertversprechen, es ist einfach... falsch. Die Modelle, die Sie wirklich wollen, befinden sich in der oberen rechten Ecke: Deepseek 3.1 (effizient UND akkurat), Claude Sonnet 4.5 (ausgewogenes Biest) und Grok Code Fast (solider Allrounder). Die Mikroblase von GPT-5 bestätigt, dass es die teure Option ist.
Was haben wir also gelernt?
- Genauigkeit ist nicht alles. Ein Modell, das etwas genauer ist, aber doppelt so lange braucht - und fünfmal so viele Token verbrennt - ist vielleicht nicht die beste Wahl. In einer SOC sind Effizienz und Umfang Teil der Genauigkeit.
- Die Verwendung von Werkzeugen ist ein Fenster zur Argumentation. "Wenn ein LLM zehn Tool-Aufrufe benötigt, um eine einfache Frage zu beantworten, ist es nicht gründlich - es ist verloren. Die leistungsstärksten Modelle haben nicht nur die richtige Antwort gefunden, sondern sind auch effizient mit ein oder zwei intelligenten Abfragen durch den MCP zum Ziel gekommen. Bei der Verwendung von Tools geht es nicht um Quantität - es geht darum, wie schnell das Modell den richtigen Weg findet. Es ist nicht immer das LLM, das schuld ist. Ein guter MCP-Server ist für einen optimalen Tool-Aufruf unerlässlich. Aber heben wir uns die MCP-Bewertung für einen späteren Zeitpunkt auf.
- Die Gestaltung von Aufforderungen wird unterschätzt. Die kleinste Änderung im Wortlaut kann die Genauigkeit oder die Halluzinationsraten stark beeinflussen. Wir haben die Aufforderung absichtlich minimal gehalten - als Grundlage für künftige Anpassungen - aber es ist klar, dass kleine Designentscheidungen große Auswirkungen haben.
Zusammenfassung (und ein kleiner Realitätscheck)
Es geht also nicht wirklich darum, welches Modell einen Schönheitswettbewerb gewinnt. Sicher, der GPT-5 könnte den Claude in der einen oder anderen Hinsicht ausstechen, aber das geht am Thema vorbei.
Die eigentliche Lektion ist, dass die Evaluierung Ihres KI-Agenten nicht optional ist.
Wenn Sie sich in Ihrem SOC auf GenAI verlassen wollen - um Alarme zu sortieren, Vorfälle zusammenzufassen oder sogar Eindämmungsmaßnahmen einzuleiten - dann müssen Sie wissen, wie sie sich verhält, wo sie versagt und wie sie sich im Laufe der Zeit entwickelt.
KI ohne Bewertung ist nur Automatisierung ohne Verantwortlichkeit.
Und ebenso wichtig: Ihre Sicherheitstools müssen LLM sprechen.
Das bedeutet strukturierte Daten, saubere APIs und Kontext, der maschinenlesbar ist und nicht in Dashboards oder Anbietersilos eingeschlossen ist. Das fortschrittlichste Modell der Welt kann nicht vernünftig arbeiten, wenn es mit halb kaputten Telemetriedaten gefüttert wird.
Deshalb sind wir bei Vectra AI besessen davon, sicherzustellen, dass unsere Plattform - und unser MCP-Server - von vornherein LLM-fähig sind. Die Signale, die wir erzeugen, sind nicht nur für Menschen gedacht, sondern auch für Maschinen, für KI-Agenten, die denken, bereichern und handeln können.
Denn bei der nächsten Welle von Sicherheitsoperationen reicht es nicht aus, KI einzusetzen - Ihr gesamtes Ökosystem muss KI-kompatibel sein.
Das SOC der Zukunft ist nicht nur KI-gesteuert. Es ist KI-gemessen, KI-verbunden und KI-bereit.